 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboSemanticBench: Diagnosing Semantic Grounding in Action Prediction for VLA Models
Jun 01, 2026Vision-language-action (VLA) models are built on the premise that semantic understanding from pretrained language or vision-language backbones should guide robot action prediction. Yet robot fine-tuning is optimized as imitation over task-specific action distributions, and many evaluations can be solved through visual or instruction-action shortcuts. We introduce RoboSemanticBench (RSB), an embodied benchmark for diagnosing semantic grounding in action prediction: whether post-trained VLA models can use complex instruction semantics to select and manipulate the correct physical target. In each episode, a robot receives a multiple-choice math or general-knowledge question, observes candidate answer blocks, and must grasp the block corresponding to the correct answer. RSB covers controlled arithmetic, grade-school mathematical understanding, and commonsense or factual understanding under four-choice and ten-choice suites. Across representative VLA models, we find that many policies learn to grasp candidate blocks but select the semantically correct block at near-random or below-random rates after controlling for grasp success, revealing a persistent gap between backbone-level semantic competence and action prediction.
IntentVLA: Short-Horizon Intent Modeling for Aliased Robot Manipulation
May 14, 2026Robot imitation data are often multimodal: similar visual-language observations may be followed by different action chunks because human demonstrators act with different short-horizon intents, task phases, or recent context. Existing frame-conditioned VLA policies infer each chunk from the current observation and instruction alone, so under partial observability they may resample different intents across adjacent replanning steps, leading to inter-chunk conflict and unstable execution. We introduce IntentVLA, a history-conditioned VLA framework that encodes recent visual observations into a compact short-horizon intent representation and uses it to condition chunk generation. We further introduce AliasBench, a 12-task ambiguity-aware benchmark on RoboTwin2 with matched training data and evaluation environments that isolate short-horizon observation aliasing. Across AliasBench, SimplerEnv, LIBERO, and RoboCasa, IntentVLA improves rollout stability and outperforms strong VLA baselines
FrameSkip: Learning from Fewer but More Informative Frames in VLA Training
May 13, 2026Vision-Language-Action (VLA) policies are commonly trained from dense robot demonstration trajectories, often collected through teleoperation, by sampling every recorded frame as if it provided equally useful supervision. We argue that this convention creates a temporal supervision imbalance: long low-change segments dominate the training stream, while manipulation-critical transitions such as alignment, contact, grasping, and release appear only sparsely. We introduce FrameSkip, a data-layer frame selection framework that scores trajectory frames using action variation, visual-action coherence, task-progress priors, and gripper-transition preservation, then remaps training samples toward high-importance frames under a target retention ratio. Because FrameSkip operates only in the dataloader, it leaves the VLA architecture, action head, training objective, and inference procedure unchanged. Across RoboCasa-GR1, SimplerEnv, and LIBERO, FrameSkip improves the success-retention trade-off over full-frame training and simpler frame selection variants, achieving a macro-average success rate of 76.15% across the three benchmarks compared with 66.50% for full-frame training while using a compressed trajectory view that retains 20% of unique frames in the main setting.
3D-Mix for VLA: A Plug-and-Play Module for Integrating VGGT-based 3D Information into Vision-Language-Action Models
Mar 25, 2026Vision-Language-Action (VLA) models leverage Multimodal Large Language Models (MLLMs) for robotic control, but recent studies reveal that MLLMs exhibit limited spatial intelligence due to training predominantly on 2D data, resulting in inadequate 3D perception for manipulation tasks. While recent approaches incorporate specialized 3D vision models such as VGGT to enhance spatial understanding, they employ diverse integration mechanisms without systematic investigation, leaving the optimal fusion strategy unclear. We conduct a comprehensive pilot study comparing nine VGGT integration schemes on standardized benchmarks and find that semantic-conditioned gated fusion, which adaptively balances 2D semantic and 3D geometric features based on task context, achieved the strongest performance among all nine evaluated fusion schemes in our pilot study. We present 3D-Mix, a plug-and-play module that integrates into diverse VLA architectures (GR00T-style and $π$-style) without modifying existing MLLM or action expert components. Experiments across six MLLM series (nine model variants, 2B--8B parameters) on SIMPLER and LIBERO show that 3D-Mix delivers consistent performance gains, averaging +7.0% on the out-of-domain (OOD) SIMPLER benchmark across all nine GR00T-style variants, establishing a principled approach for enhancing spatial intelligence in VLA systems.
MoTiAC: Multi-Objective Actor-Critics for Real-Time Bidding
Feb 18, 2020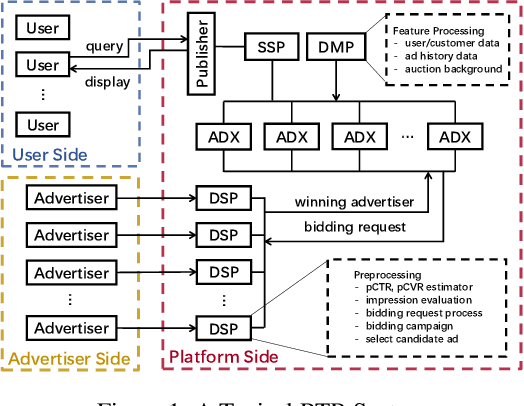
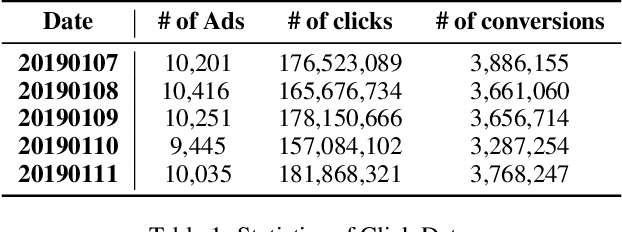
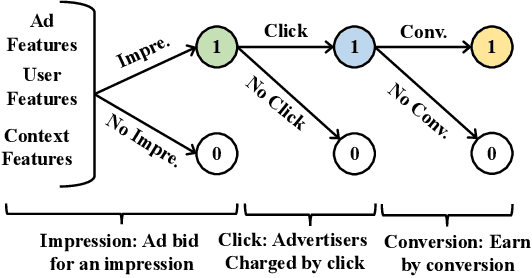
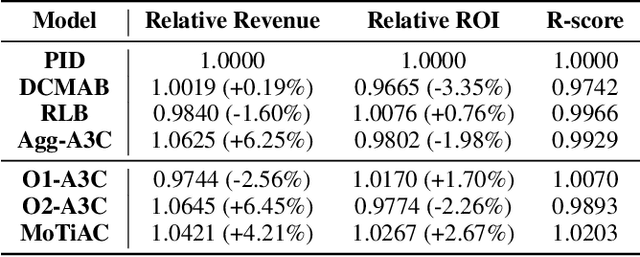
Online real-time bidding (RTB) is known as a complex auction game where ad platforms seek to consider various influential key performance indicators (KPIs), like revenue and return on investment (ROI). The trade-off among these competing goals needs to be balanced on a massive scale. To address the problem, we propose a multi-objective reinforcement learning algorithm, named MoTiAC, for the problem of bidding optimization with various goals. Specifically, in MoTiAC, instead of using a fixed and linear combination of multiple objectives, we compute adaptive weights overtime on the basis of how well the current state agrees with the agent's prior. In addition, we provide interesting properties of model updating and further prove that Pareto optimality could be guaranteed. We demonstrate the effectiveness of our method on a real-world commercial dataset. Experiments show that the model outperforms all state-of-the-art baselines.
Measuring Long-term Impact of Ads on LinkedIn Feed
Jan 29, 2019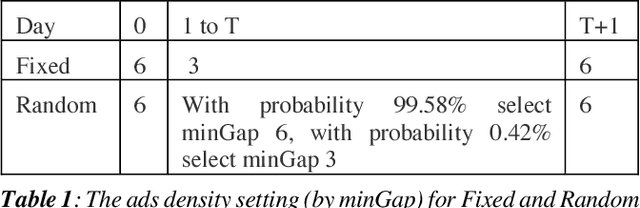
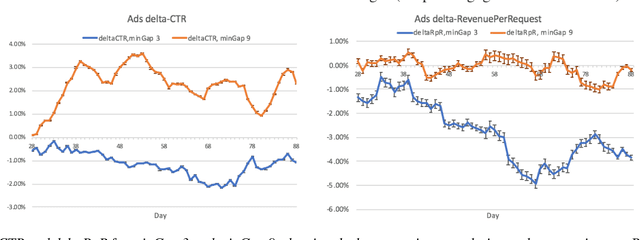
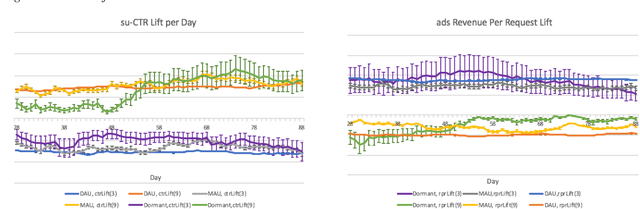
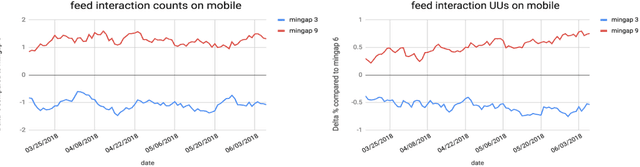
Organic updates (from a member's network) and sponsored updates (or ads, from advertisers) together form the newsfeed on LinkedIn. The newsfeed, the default homepage for members, attracts them to engage, brings them value and helps LinkedIn grow. Engagement and Revenue on feed are two critical, yet often conflicting objectives. Hence, it is important to design a good Revenue-Engagement Tradeoff (RENT) mechanism to blend ads in the feed. In this paper, we design experiments to understand how members' behavior evolve over time given different ads experiences. These experiences vary on ads density, while the quality of ads (ensured by relevance models) is held constant. Our experiments have been conducted on randomized member buckets and we use two experimental designs to measure the short term and long term effects of the various treatments. Based on the first three months' data, we observe that the long term impact is at a much smaller scale than the short term impact in our application. Furthermore, we observe different member cohorts (based on user activity level) adapt and react differently over time.